WEKA
Weka是一个University of Waikato用java编写的开源机器学习软件,有着自己的GUI界面,内置了很多算法工具,适合我这种半吊子手残。IBM有一篇比较详细的教程了。
在官网下载好weka,接下来使用经典的鸢尾花卉数据集进行测试。这个数据集有150条数据,几个数据分别是sepal_length,sepal_width,petal_length,petal_width以及class。接下来,随机选130条作为训练集,剩下的20条作为测试集,测试一下对class的预测。
数据处理
然后需要将数据处理成arff格式,像下面这样,这里最好保证class在第一列或者最后一列,方便后面使用。
@RELATION iris
@ATTRIBUTE sepal_length NUMERIC
@ATTRIBUTE sepal_width NUMERIC
@ATTRIBUTE petal_length NUMERIC
@ATTRIBUTE petal_width NUMERIC
@ATTRIBUTE class {setosa, versicolor, virginica}
@DATA
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5.0,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
测试组我会把class弄成问号,不弄好像也可以,会在输出结果显示是否一致。
@RELATION iris
@ATTRIBUTE sepal_length NUMERIC
@ATTRIBUTE sepal_width NUMERIC
@ATTRIBUTE petal_length NUMERIC
@ATTRIBUTE petal_width NUMERIC
@ATTRIBUTE class {setosa, versicolor, virginica}
@DATA
4.9,3.1,1.5,0.1,?
5.4,3.7,1.5,0.2,?
4.9,3.1,1.5,0.1,?
4.4,3.0,1.3,0.2,?
5.1,3.4,1.5,0.2,?
WEKA使用
打开weka,选择Explorer,然后Open file打开训练集,再点Classify标签。
在Choose里可选内置的算法,可选择Use training set,其实Cross-validation也可以,然后点Start。对半桶水的我来说,当然是把所有都选一遍看哪个模型出来的TPR最高。
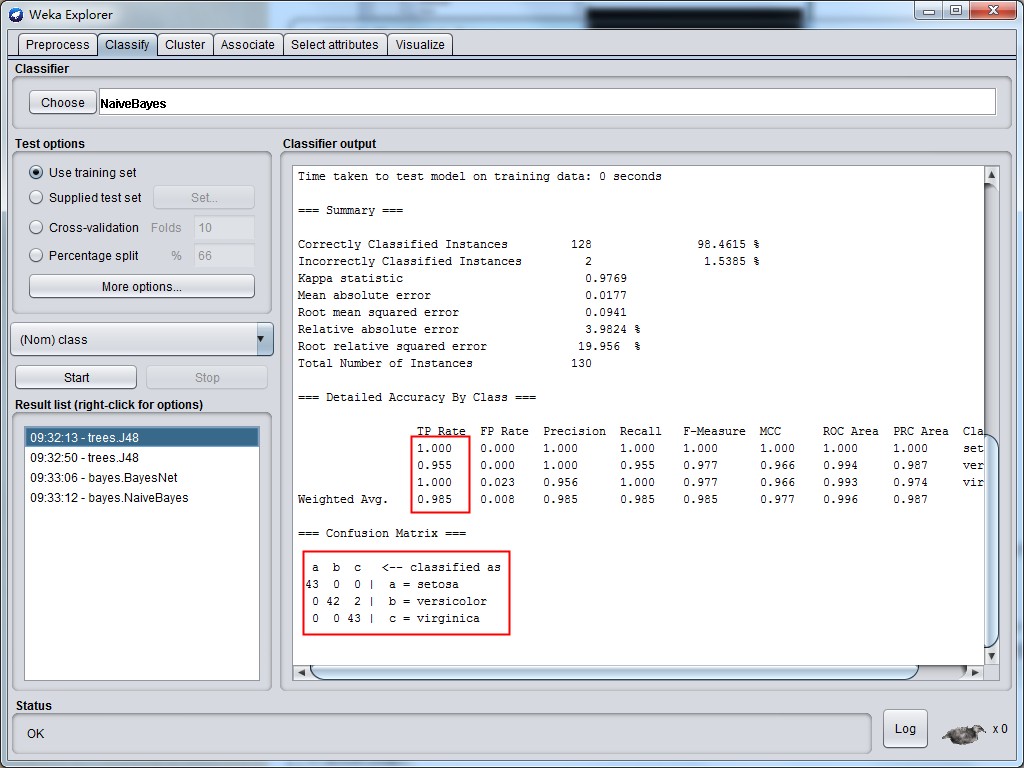
就这样,最后选了这个J48算法。在Result list中,对该算法右键,然后Save model。接下来是对测试集进行预测。重新打开一个Explorer窗口,导入测试集。然后在Classify标签中选择Supplied test set。点击set,再次导入测试集,同时确定Class里选对了class,点击Close关闭。在More options的Output predictions里选择输出格式为CSV。
然后在Result list中右键选择Load model,导入刚才使用训练集生成的model。再右键选择Re-evalute model on current test set,在右侧窗口就可以看到测试集的预测结果了。
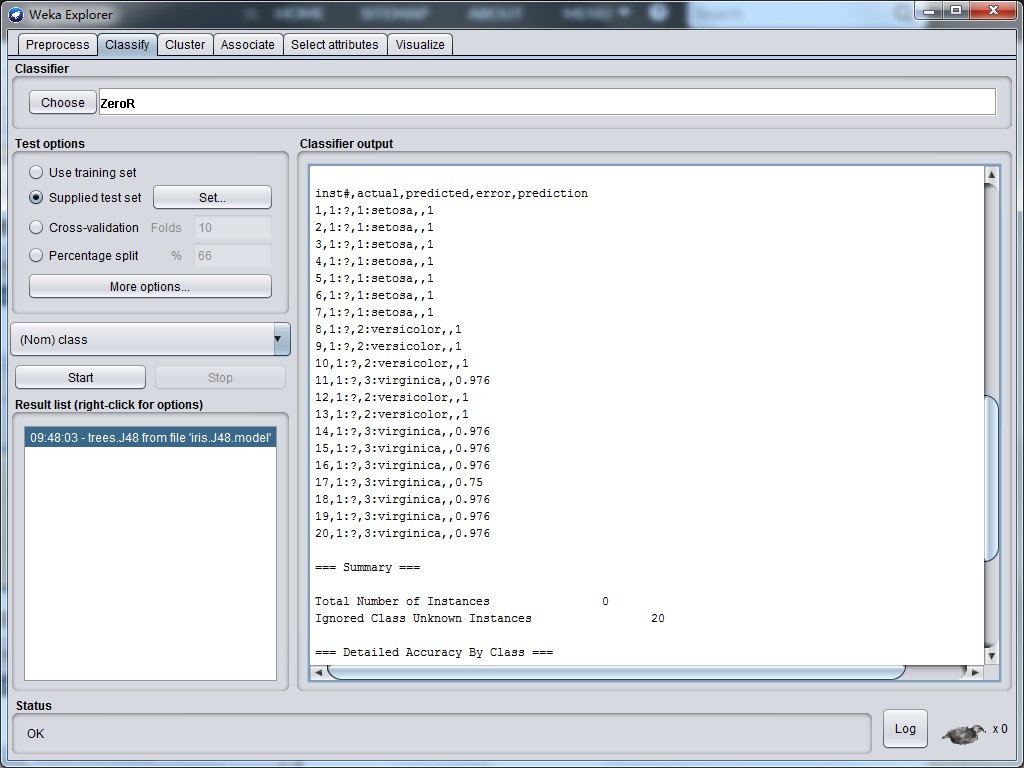
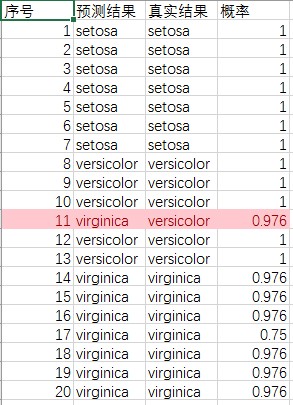
现在可以在Result list中右键选择Save result buffer把结果保存下来,和原结果对比,发现20个样本中有一个预测错误。
python-weka-wrapper3
使用GUI对于流水线工人来说不是什么长久之计,针对一个项目还是把流程固定下来比较好,python-weka-wrapper3这个包可以调用weka的api。
安装相关的依赖,没有root权限也可以试一试能不能装
sudo apt-get install python3-pil python3-matplotlib python3-pygraphviz
sudo pip3 install javabridge
sudo pip3 install python-weka-wrapper3
看了半天文档,调来调去,勉强跑通了。需要import的有下面这些。
import weka.core.jvm as jvm
from weka.core.converters import Loader
from weka.classifiers import Classifier
from weka.classifiers import FilteredClassifier
from weka.classifiers import Evaluation
from weka.core.classes import Random
import weka.core.serialization as serialization
然后是建立model的方法
def TrainingModel(arff, modelOutput):
# 启动java虚拟机
jvm.start()
# 导入训练集
loader = Loader(classname="weka.core.converters.ArffLoader")
train = loader.load_file(arff)
# 注意这里,要设定class是在哪里
train.class_is_last()
clsf = Classifier(classname="weka.classifiers.trees.J48")
clsf.build_classifier(train)
# 建立模型
fc = FilteredClassifier()
fc.classifier = clsf
evl = Evaluation(train)
evl.crossvalidate_model(fc, train, 10, Random(1))
# 保存模型
clsf.serialize(modelOutput, header=train)
# 退出虚拟机
jvm.stop()
运行上面,成功得到model文件。 然后建立导入测试集和model,获得结果的方法。
def TestClassification(arff, modelInput, results):
# 启动java虚拟机
jvm.start()
# 导入分析模型
objects = serialization.read_all(modelInput)
clsf = Classifier(jobject=objects[0])
print(clsf)
# 导入测试组
loader = Loader(classname="weka.core.converters.ArffLoader")
test = loader.load_file(arff)
test.class_is_last()
# 分析结果
resultsFile = open(results, "w")
resultsFile.write("序号\t预测\n")
for index, inst in enumerate(test):
pred = clsf.classify_instance(inst)
dist = clsf.distribution_for_instance(inst)
sampleID = index + 1
origin = inst.get_string_value(inst.class_index)
prediction = inst.class_attribute.value(int(pred))
resultsFile.write("%d\t%s" % (sampleID, prediction) + "\n")
resultsFile.close()
# 退出java虚拟机
jvm.stop()
获得一致的分析结果,也是20个里面有一个被分类错误了。