直接用awk命令
awk '{if(NR%4==2) print length($1)}' read.fastq | sort -n | uniq -c > reads_length.txt
NR%4==2的意思是以每四行为一个组,统计每组的第二行(在fastq文件中就是碱基信息行)。
然后用R
library(ggplot2)
reads <- read.csv('reads_length.txt', sep=' ', header=FALSE)
ggplot(reads, aes(x=reads$V2, y=reads$V1)) +
geom_bar(stat='identity') +
xlab('read length') +
ylab('counts') +
ggtitle('Read Length Distribution')
直接用plot也可以,但是ggplot2画出来比较好看。
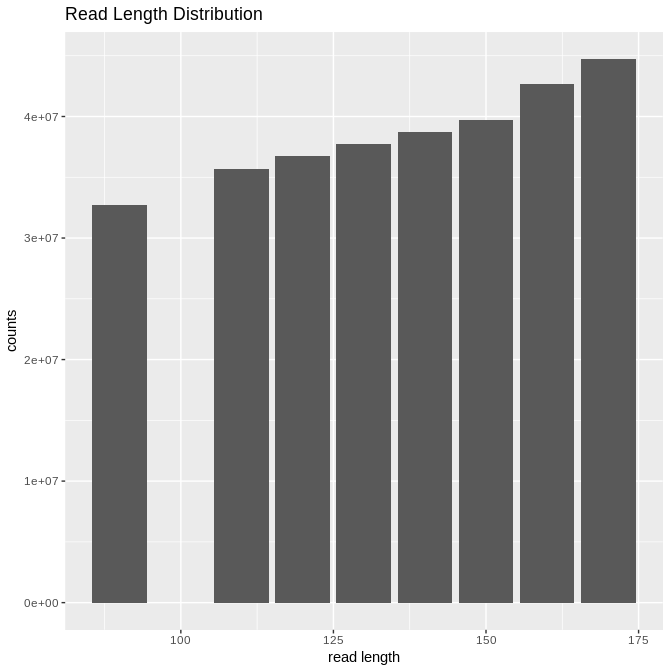 结果就是这样。
结果就是这样。
另外,对于被做过修剪质控的数据,这样做是没有意义的,因为那种数据只会有一个固定的读长。