经历Snakemake与WDL之间的反复横跳之后,我还是决定学习WDL。主要学习路线是WDL的语法以及Cromwell的使用。
WDL
WDL全称是Workflow Description Language,是Broad Institute专门开发用来跑流程的语言。由于是需要快速建立流程,因此这个语言的特点就是可以快速编写,简单易懂(我还是觉得Snakemake比较容易上手)。
WDL基本元件有5个,分别是定义总流程的workflow、定义单个任务的task、运行任务的call、定义任务中命令的command以及输出output。
下面将以bwa比对流程为例,展示WDL的语法。WDL支持以“#”作为注释,另外为了格式规范,建议使用四个空格作为缩进。首先在WDL脚本中,需要声明WDL的版本,这里写version 1.0声明为WDL 1.0。除此之外,WDL还有draft1,draft2等版本(version 1.0即draft3)。我没有去研究过不同版本间的差异,目前1.0应该是比较规范的。另外,也可以使用womtools将编写的WDL脚本转为1.0版本。
# 定义版本
version 1.0
开始前,先写一个bwa的运行任务。由于后续使用Cromwell运行时,会将所有输入文件硬链接到Cromwell的任务路径中,同时Cromwell会将所有的脚本命令,输出文件等均输出到任务路径中,因此,不建议在输入输出中加入文件夹路径,建议文件直接使用文件名。
当然,指定其他的绝对路径进行输出也是可以的,但是这样做输出文件会输出在Cromwell引擎外的文件夹下,会导致的问题有,如果一个任务中有多条命令,同时使用docker来作为环境时,docker会找不到文件。因为Cromwell默认是把自己的目录挂载到docker中(这也解析了为什么WDL必须传入所有的输入文件,包括索引文件)。如果必须使用其他路径,可以用硬链接在完成后再链接回去。
task bwa {
input {
File read1
File read2
String sample
Int? threads = 8
}
File reference = "hg19.fa"
File ref_fai = "hg19.fa.fai"
File ref_bwt = "hg19.fa.bwt"
File ref_amb = "hg19.fa.amb"
File ref_ann = "hg19.fa.ann"
File ref_pac = "hg19.fa.pac"
File ref_sa = "hg19.fa.pac"
String test = "test/~{sample}/xxx"
command <<<
bwa mem -t ~{threads} \
~{reference} ~{read1} ~{read2} \
| sambamba view -f bam \
-S /dev/stdin -t ~{threads} > ~{sample}.bam
sambamba sort ~{sample}.bam \
-t ~{threads} -o ~{sample}.sort.bam
python3 <<CODE
print("done")
CODE
>>>
output {
File sortBam = "~{sample}.sort.bam"
File sortBamBai = "~{sample}.sort.bam.bai"
}
runtime {
docker: "pzweuj/mapping"
}
}
在WDL 1.0中,task需要写input项,将变量与其他默认传入的项目进行区别。另外,command的括号有两种写法,一种是“~{}”,这样写的话内容中引用必须是“${}”,而写为“<<<>>>”的话,内容中的引用需要是“~{}”(实测了也不一定,两种方式可同时存在,因此我把~用于来自command line外部的参数,而$用于来自command line内部的)。另外,command中可以插入代码内容,如例子所示。需要注意的是,在command中,由于也是以换行来判断命令执行的,因此也要注意换行符是“\r\n”还是“\n”。而output中需要注意的是必须用引号圈起输出。最后,runtime不是必须要指定的,但是,使用docker将软件进行封装来确保运行环境兼容性才应该是最佳策略,因此这里建议使用docker环境。如上面脚本中的test,还可以这样建立新的量,String内容可以使用“+”来合并,也有“if xxx then xxx else xxx”的方法。
每个输入输出都需要设定类型,类型有File、String、Int、Float、Boolean、Array、Map、Object。当在变量后加入“?”即代表变量可选,非必要。在定义完成任务task后,可以定义workflow流程。
workflow test {
input {
File my_read1
File my_read2
String my_sample
}
call bwa as mapping {
input:
read1 = my_read1,
read2 = my_read2,
sample = my_sample
}
}
就这样,完成了比对的任务。同时,可以如果read的来源是上一个QC任务,结果可以直接导入到其他任务中,例子如下
workflow test {
input {
File my_read1
File my_read2
String my_sample
}
call QC {input: ...}
call bwa as mapping {
input:
read1 = QC.cleanRead1,
read2 = QC.cleanRead2,
sample = my_sample
}
}
前提是QC中定义的输出cleanRead1和cleanRead2。有些时候,我们并不是在一个脚本中定义task和workflow,而是分开多个脚本。我是这样做的,把用的上的task都写入到脚本中,往后建立workflow只要导入这些task即可。WDL中的导入方式例子如下,如我在test.wdl中写了一个bwa task.
import "test.wdl" as test
workflow {
input {}
call test.bwa as mapping {input: ...}
}
同时,WDL可以多次调用同一个task,但是必须使用“as”来定义一个不同的别名用以区分。
还有一个值得学习的功能是scatter。通过Array变量定义输入,就可以使用scatter来批量调用同一个任务,写法如下
Array[File] inputFiles
scatter (oneFile in inputFiles) {
call stepA {input: in=oneFile}
}
call stepB {input: files=stepA.out}

更多WDL的语法,可参阅这篇文章。对于WDL的编写格式规范,可看这个网站。
Womtools
在完成WDL脚本后,可以先使用Womtool来进行验证流程是否可行。我分别对womtool和cromwell都建立了运行别名。
alias womtool="java -jar womtool-62.jar"
alias cromwell="java -Dconfig.file=test.config cromwell-62.jar"
使用womtool验证流程,下面这条命令会输出是否存在错误,并定位。需要注意的是使用windows来写WDL时,往往会出现换行符为”\r\n”导致WDL报错的情况,可以使用sed来替换。
womtool validate pipeline.wdl
sed -i 's/\r//g' pipeline.wdl
womtool用得比较多的还有画流程图
womtool graph pipeline.wdl | dot -Tsvg > pipeline.svg
还有就是将WDL脚本升级到1.0的命令,但是我测试使用这个出来的脚本还是挺多格式问题的,因此不建议使用,还是老老实实自己写比较好。
womtool upgrade pipeline.wdl > pipeline.1.wdl
当然,最后这个是用得最多的,将WDL脚本的输入项导出为json格式,后面就可以使用cromwell来运行了。
womtools inputs pipeline.wdl > pipeline.json
Cromwell

最后就是Cromwell这个引擎,由图可知用途就是给WDL这只蠢猪加上火箭一飞冲天。Cromwell有两个基本用法,一个是服务器版的
java -jar cromwell.jar server
另外一个是直接运行单个项目
java -jar cromwell.jar run pipeline.wdl -i pipeline.json
这里先说单个项目的运行,除了上面的基本命令外,还可以指定其他的运行参数。首先是Cromwell的全局配置,可以参阅Cromwell的文档。我是去下载这个模板来改。在运行Cromwell时,使用以下命令来调整cromwell的配置。
java -Dconfig.file=cromwell.conf cromwell.jar
这里建议是打开call-caching 的选项,可以在任务断掉时,使用已完成项来重新接续运行,而不用从头运行。
另外,对于单个Workflow,即单个WDL,还可以设置单独的参数,也是使用json文件来设置,可以参阅这篇。运行时,加入“-o”参数来指定。这个配置文件中也能重新指定输出文件的文件夹。
java -Dconfig.file=cromwell.conf -jar cromwell.jar run pipeline.wdl -i pipeline.json -o config.json
对于import了其他wdl文件的WDL脚本,建议做法是将需要import的wdl文件压缩到一个zip里面,然后使用cromwell中的import命令导入。
java -Dconfig.file=cromwell.conf -jar cromwell.jar run pipeline.wdl -i pipeline.json -o config.json --imports resource.zip
最终,运行结束会呈现的目录结构如下
final_workflow_outputs_dir
-my_workflow
-ade68a6d876e8d-8a98d7e9-ad98e9ae8d
-call-my_one_task
-execution
-my_output_picture.jpg
-input
其中my_workflow是WDL中的workflow名,ade68a6d876e8d-8a98d7e9-ad98e9ae8d是本次运行随机生成的ID,下面则是每个任务,任务下是输入和输出。
对于Cromwell的服务器版,可使用以下命令开启。
java -Dconfig.file=cromwell.conf -jar cromwell.jar server
服务器版的基本设置看这里。
服务器端开放了一些API接口用于获取运行信息,可以通过打开 http://localhost:8000 (默认)来查看API接口。另外,Broad也提供了一个官方工具widdler用来进行作业提交或获取运行信息。试用了以下,感觉并不好用而且很久没有更新了。还有另外一个软件Cromshell,用起来可以但是只是简单调用API提取返回的json的感觉。我发现了另外一个工具oliver,用起来比较舒服,这个工具依赖于Rust,由于我不用conda,安装时主要坑在于cryptography的安装。如果出现segmentation fault的情况可以考虑先“apt remove python3-crytography”。再pip重新安装。
另外,Oliver基于python3.7,在python3.6版本以下使用会有问题。我在python3.6下使用需要修改”~/.local/lib/python3.6/site-packages/oliver/__main__.py”第125行
def main() -> None:
# asyncio.run(run())
loopFix = asyncio.get_event_loop()
loopFix.run_until_complete(run())
虽然偶尔会崩,不过能用了。软件其他使用方式见官网。
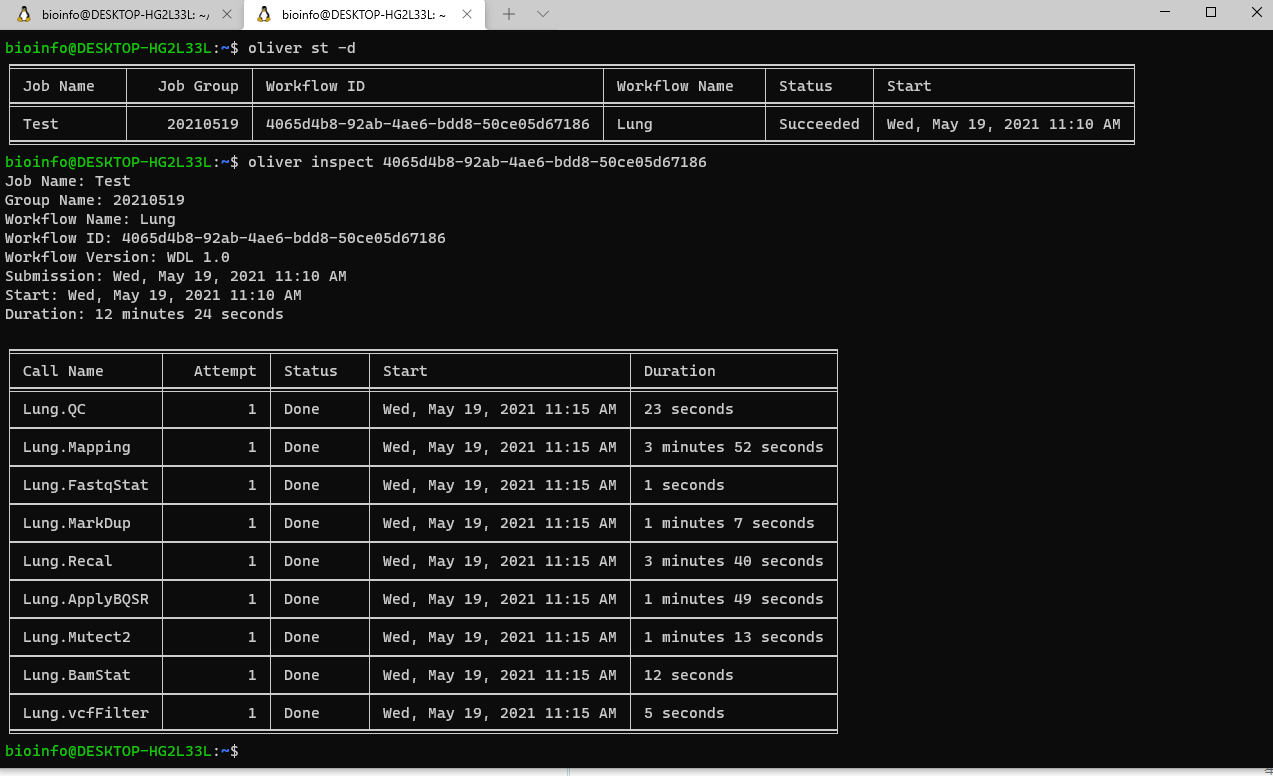
使用效果还是比较理想的。
使用笔记
在slurm集群中搭建Cromwell引擎。在进行多任务投递后,运行一段时间后会出现ssh断连的情况,同时cromwell后台也会中断。由于我的cromwell是在后台运行,因此排除是由于ssh超时导致的中断。原因应该是由于控制节点也参与了运算,导致在控制节点完成计算后,slurm清空节点的进程使服务断开。重新设置slurm的config文件,将控制节点去掉后重新在控制节点中启动cromwell服务,成功执行。