使用腾讯云WorkBuddy的Openclaw爬取OncoKB(可行)
#default
最近龙虾热潮,巨头们现在在卷龙虾应用。腾讯这个鸡贼的,把自己的CodeBuddy魔改了一下(感觉是把vscode的代码窗口直接砍掉,然后留着对话窗口和工作区),上线了WorkBuddy。
我感觉这个WorkBuddy并没有实现原本龙虾的功能,甚至感觉不像龙虾,而是一个普通的Claude Code加上GUI。不过话说回来,该薅还是要薅的。
WorkBuddy
好的,现在进入正题,让WorkBuddy的Claw模式(Plan)来爬取OncoKB,还是用之前给Manus的提示词。模型我使用的是Minimax-M2.5
提示词
任务目标: 从OncoKB网站提取基因位点(Alterations)的详细描述信息以及相关的治疗、诊断、预后和FDA认可内容,并最终整理成5个结构化的表格。
流程步骤:
第一步:访问初始列表页
打开您的Web浏览器。
输入或点击以下链接,访问OncoKB网站的Alterations页面:
https://www.oncokb.org/actionable-genes
在此页面,您将看到一个所有基因位点(Alterations)的列表。这个列表将作为后续操作的基础。
第二步:逐个访问位点详情页并提取描述信息
对于列表中的每一个基因位点(例如:EGFR L858R, KRAS G12C 等),点击其对应的链接,进入该位点的详情页面。
在每个详情页的顶部或描述区域,请仔细查找并记录以下信息,这些信息将构成第一个表格的行数据:
基因名称 (Gene Symbol): 例如:EGFR, TP53, KRAS。
位点名称 (Alteration Name): 例如:L858R, G12C, Amplification。
Oncogenic Status: 描述该位点的致癌性,例如:Oncogenic, Likely Oncogenic, Neutral, Inconclusive等。
Function: 描述该位点是“Gain-of-function”(功能获得)还是“Loss-of-function”(功能缺失),或无特定描述。
Mutation Type (如果明确提及): 变异类型,例如:Missense, Truncating, Fusion, Amplification, Deletion等。
参考基因组 (Reference Genome): 如果页面有明确显示,例如:GRCh37 / GRCh38。
基因总结信息 (Gene Summary): 位于页面顶部或“Summary”部分的,对该基因功能、作用机制等的高层次概括。请摘取主要观点或概述性描述。
第三步:提取各标签页的表格数据
在每个基因位点详情页中,您会看到以下几个标签(通常在页面下方或侧边栏):
Therapeutic
Diagnostic
Prognostic
FDA-Recognized Content
逐一点击每个标签。当您点击一个标签后,页面会加载出该标签对应的表格内容。
完整地复制并粘贴该标签页下的整个表格数据。确保所有列的标题和对应的行数据都被准确地提取。
第四步:数据整理与最终输出
将所有收集到的数据整理成5个独立的表格。
建议使用电子表格软件(如Excel或Google Sheets),创建5个不同的工作表(Sheet),每个工作表对应一个表格。
最终输出表格结构示例:
1. 基因与位点的信息表 (Gene and Alteration Information Table)
示例列:
基因名称 (Gene Symbol)
位点名称 (Alteration Name)
Oncogenic Status
Function (Gain-of-function/Loss-of-function)
Mutation Type
参考基因组 (Reference Genome)
基因总结信息 (Gene Summary)
2. Therapeutic 表
包含从每个位点的“Therapeutic”标签页提取的所有表格数据。
列名与OncoKB网页上的表格列名保持一致。
3. Diagnostic 表
包含从每个位点的“Diagnostic”标签页提取的所有表格数据。
列名与OncoKB网页上的表格列名保持一致。
4. Prognostic 表
包含从每个位点的“Prognostic”标签页提取的所有表格数据。
列名与OncoKB网页上的表格列名保持一致。
5. FDA-Recognized Content 表
包含从每个位点的“FDA-Recognized Content”标签页提取的所有表格数据。
列名与OncoKB网页上的表格列名保持一致。
重要提示:
OncoKB网站的数据量较大,请确保耐心和细致地完成每个步骤。
在提取表格数据时,尤其注意复制粘贴的完整性,确保不遗漏任何行或列。
建议定期保存您的工作进度,以防数据丢失。
如果在任何步骤遇到疑问或不确定如何提取某个特定信息,请及时向我反馈。
WorkBuddy工作
WorkBuddy首先去查询了OncoKB是否有提供API接口,同时他开始让我确认计划
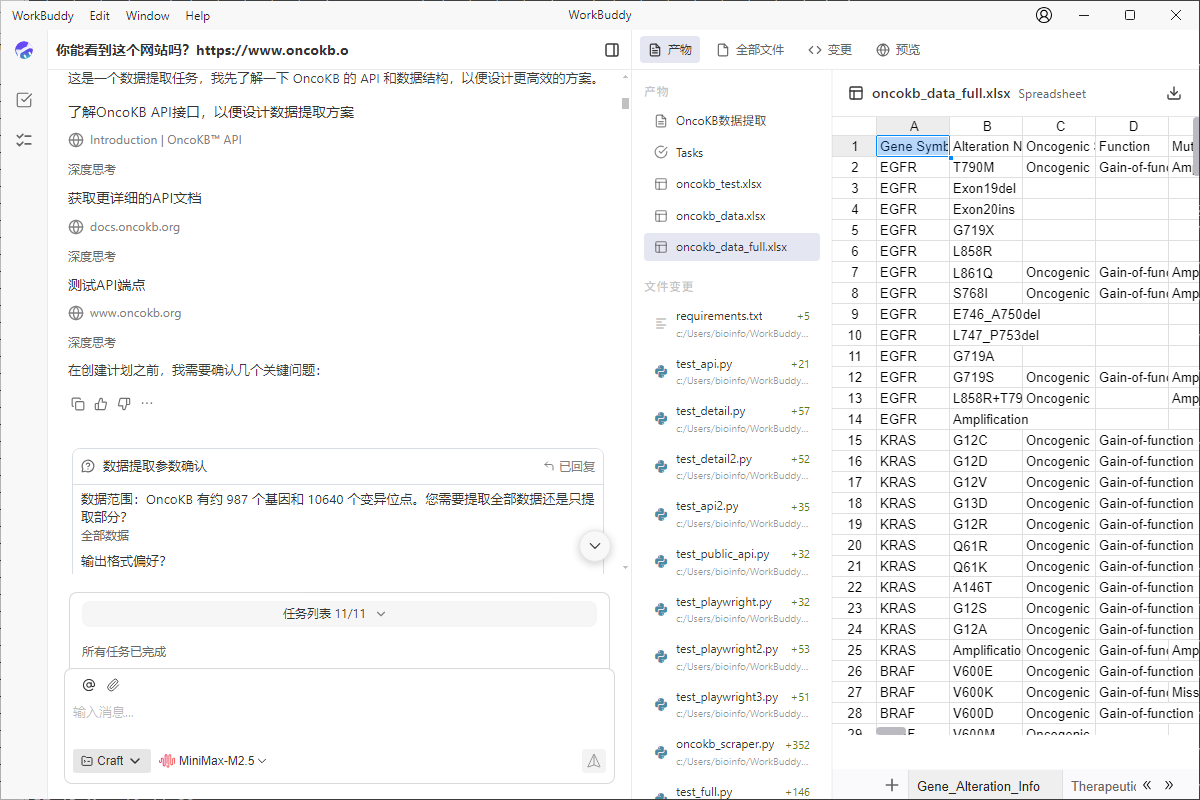
在确认计划后,WorkBuddy开始在工作区里自行构建爬虫代码,并且开始去自行整理网页的信息。但是,它爬了几个基因就停止了。它说爬取完整的耗时很长,因此,在反复拉扯下,我给了一个新的指示:
我说了,需要完整的数据,我不管需要几个小时,你只要持续运行到任务完成。你自己需要监控任务的进度,如果在未完成前就中断了,你自己要重新启动
好像还可以哦
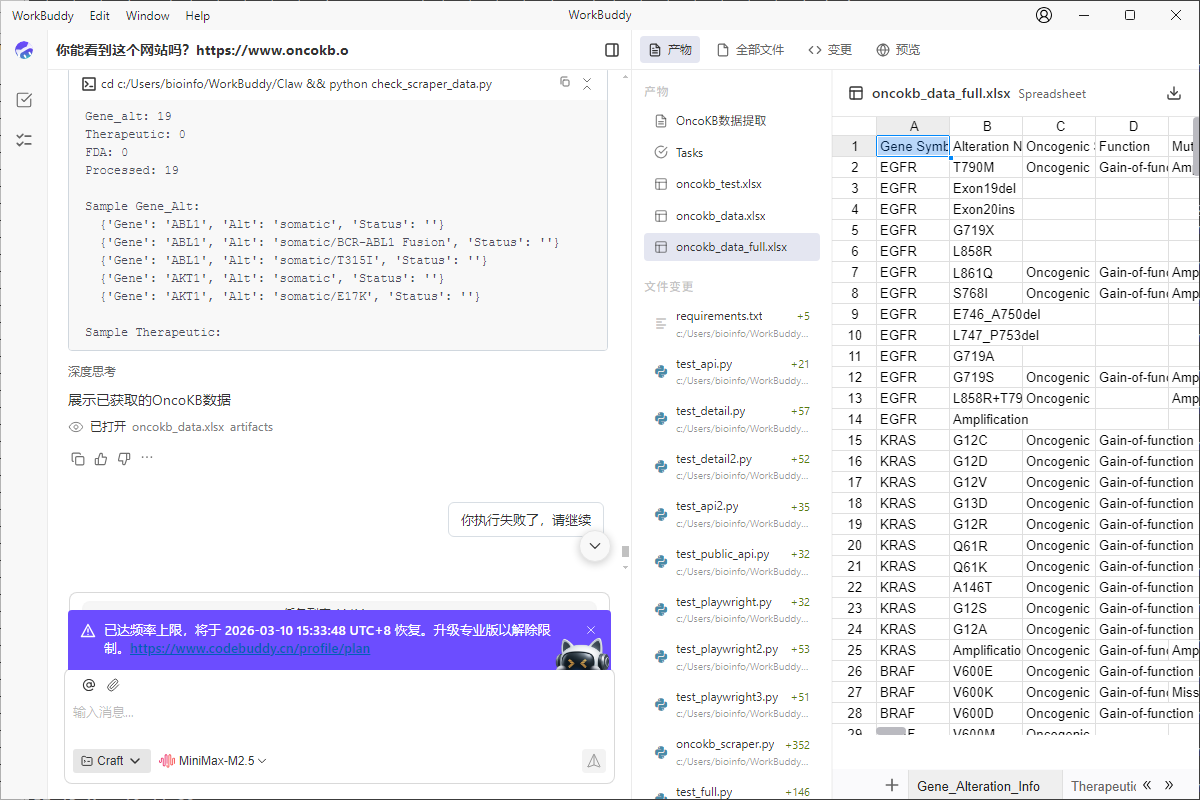
这次执行的时间很长,但是还是停了。提示是已达频率上限,需要在两小时后恢复或升级到专业版。老套路了。我并没有搜到这个频率上限是多少,因此,我还是回归自己部署的龙虾了,workbuddy已卸载。
赛后总结
- 龙虾自带的
web_fetch用来爬虫是可行的 - WorkBuddy是一个赶工出来的半成品,而且没有龙虾的那种味道
- 还是自己部署API靠谱,不会工作到一半断掉
- WorkBuddy进行日常的文件整理工作应够用,编程工作不够用
- 当前建议大家先去薅阿里云或腾讯云的首月7.9 Coding Plan